ADL4D
4D Human Activity Dataset
Towards a Contextually Rich Dataset for 4D Activities of Daily Living
Zakour* · Nath* | arXiv 2402.17758
 1 / 16
1 / 16 The Gap: Long-Horizon Activity Capture
Prior Work
- DexYCB-style: Pick / Place / Handover
- H2O3D-style: Hold and Move
- H2O-style: Hold and Interact
- Atomic / minimal complexity — no temporal chaining
ADL4D
Activity modelled as Chain / Graph of actions
Activities: Making Dinner / Coffee / Breakfast, Cleaning up
Actions w Hand-Obj pair: Boil / Heat · Pour / Place / Pick · Handover / Receive · Stir / Scoop · Push / Open / Close
| Dataset | Complex | Actions | 3D Hands | 6D Obj | Inter-Subj | #Hands/Seq | Avg Fr/Seq | #Img | #Cam |
|---|---|---|---|---|---|---|---|---|---|
| FPHA | ✗ | Frame | ✓ | ✓ | ✗ | 1 | 87 | 105K | 1 |
| DexYCB | ✗ | — | ✓ | ✓ | ✗ | 1 | 73 | 582K | 8 |
| H2O | ✗ | Frame | ✓ | ✓ | ✗ | 2 | 620 | 571K | 5 |
| H2O3D | ✗ | — | ✓ | ✓ | ✗ | 2 | 234 | 76K | 5 |
| MECCANO | ✓ | Frame | ✗ | ✗ | ✗ | 2 | 15K | 300K | 1 |
| OakInk | ✗ | — | ✓ | ✓ | ✓ | 2 | 44 | 230K | 4 |
| HOI4D | ✗ | Frame | ✓ | ✓ | ✗ | 1 | 480 | 2.4M | 1 |
| As.Hands | ✓ | Frame | ✓ | ✗ | ✗ | 2 | — | 3M | 12 |
| ARCTIC | ✗ | Frame | ✓ | ✓ | ✗ | 2 | 688 | 2.1M | 9 |
| ADL4D | ✓ | Hand | ✓ | ✓ | ✓ | 2–4 | 1833 | 1.1M | 8 |
Studio & Hardware

- 📷 (8-15+ego)× Intel RealSense D435 — synchronized RGB-D (colour + depth)
- 🔵 8× OptiTrack Prime 13X — 3D marker tracking / 6 DoF rigid pose
- 💡 4× Spotlights + diffusers — controlled, uniform illumination
- ⚡ Sync options — hardware clock/post-processed synchronisation in software
- 🏗️ Custom cage rig — plug-and-play up to 15 cameras; rapid-calibration sequence
Annotation Challenge
Prior Datasets (easier)
- Single subjects, single hands
- High FPS (>30) → easier triangulation & tracking
- Short, small sequences; minimal hand pose variety
ADL4D (harder)
- Low FPS (20) / long-tailed distribution
- Multi-subject, multi-hand (up to 4 hands)
- Sparse camera coverage
✓ Rigid Body Tracking (OptiTrack)
- Reflective markers on rigid props → worked reliably
- Marker removal via inpainting succeeded
- Clean RGB output, no artefacts
✗ Hand Marker Tracking (ARCTIC-style)
- Semi-spherical/flat markers on dorsal hand surface
- Near-flat geometry → high triangulation error, marker inpainting poor
- Parametric Hand Fitting to 3D markers work, but multisubject interhand occlusions trigger frequent track drops
Landmark Detectors as Marker Proxy
Adopted Approach
- Follow DexYCB / H2O / H2O3D — use 2D landmark detector (MediaPipe/RCNNs) as marker proxy
- Triangulate across views → 3D joints; no physical markers
- Works well for single-hands but breaks in multi-hand with exponentially scaling failure
Core Failure Mode
ReID of landmarks is core to triangulation. Core to multi-view ReID is epipolar matching + filtering:
Why It Fails
- Occluded hand's epipolar lines crosses different subject's detected hand within accepted error thresholds → incorrect 3D hand
- Enhancing with stereo patch similarity / detector embeddings — tested on full-body, not cropped hand ROI; prone to failure
- Loose MANO 2D constraints — minimal improvement; often hands start merging together
- Trained detector-side classifier — best performance but limited to single-subject sequences; doesn't scale
Solution 1: GUI Human in the Loop
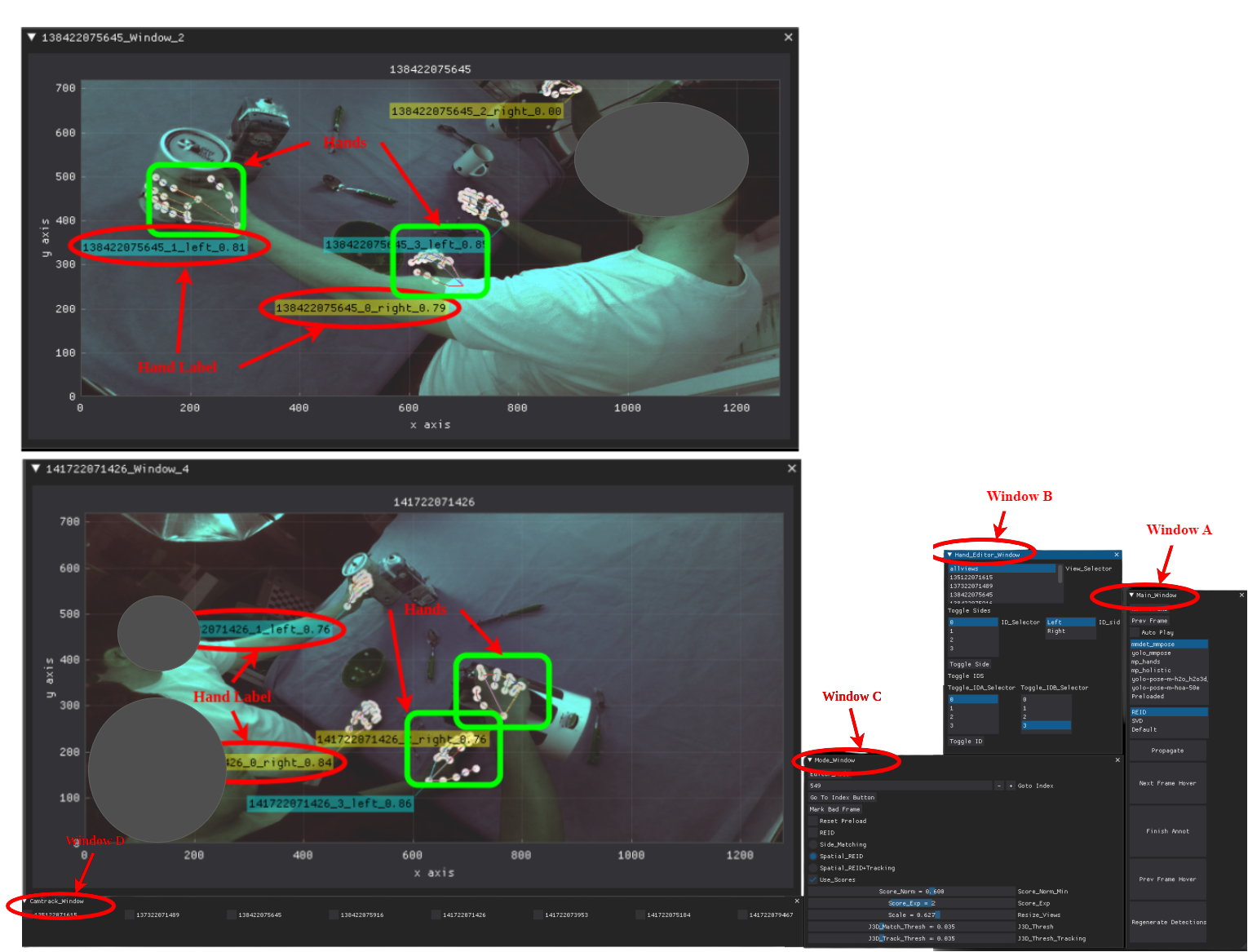
- Custom CVAT-style GUI for visually verifying and correcting locked tracks across all views
- Supports hotkey track switching, new detection triggering, live triangulation and temporal matching
- Used to annotate test set in a fully human-supervised manner
The Automation Solve: 3D Inlier Clustering & ReID
- Project ReID matching as a 3D inlier search / clustering problem
- Generate all pairwise 3D hand candidates; set assignment creates clusters that:
- Minimises/fixes number of clusters K
- Maximises 2D source detections per cluster
- Minimises final reprojection error
- Minimises pairwise 3D distance within cluster
- Propagate temporal tracks when available — enhance 3D track, prevent track drop, restore from prior dropped track
- Flag lost-track frames contrastively: interpolate hand position; mark frames as explicitly untracked
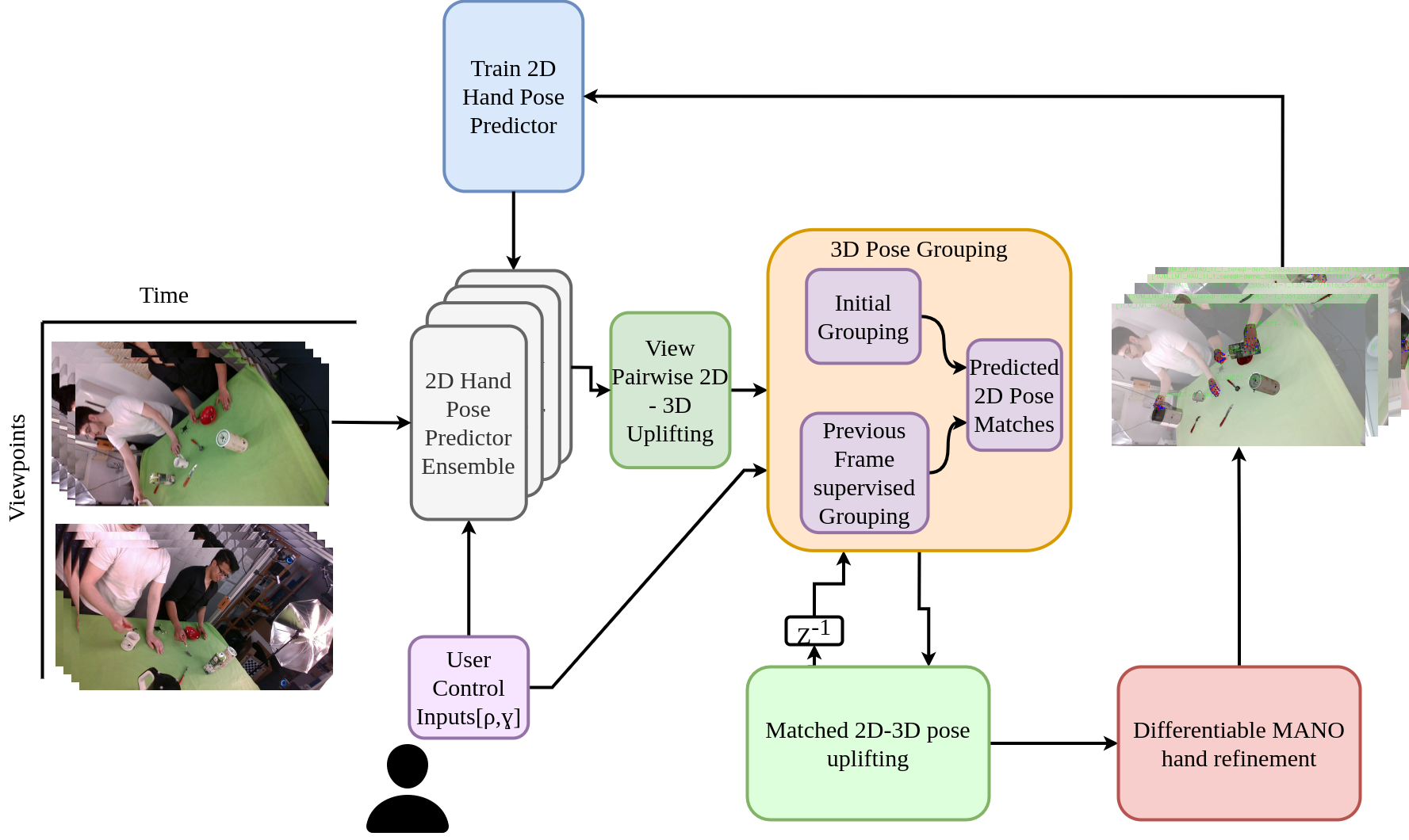
Multi-subject markerless pipeline
- Handles any number of hands in the scene
- Fully automated — no GUI needed for train/val splits
- Validated at up to 4 subjects (8 hands) at 20 FPS
- Scales to the full 1.1M frame ADL4D and external datasets without finetuning/engineering
Annotation Robustness
Skipped frames (off-the-shelf MediaPipe)
| Dataset | Without Method | With Method | Reduction |
|---|---|---|---|
| ADL4D | 1 088 | 22 | 98% |
| H2O | 6 302 | 213 | 97% |
Absolute pose accuracy on external datasets
| Dataset | abs MPJPE (mm) ↓ | AUC ↑ |
|---|---|---|
| H2O | 5.36 | 0.8930 |
| DexYCB | 8.56 | 0.8651 |
Dataset Scale & Diversity
1.1 Million annotated RGB-D frames

ADL4D (Red) covers broader pose space than H2O (Blue) and DexYCB (Green)

Includes "in-between" transitions, handovers, and idle adjustments
Downstream: Hand Mesh Recovery (HMR)
| Train Set | Test Set | MPJPE (mm) ↓ |
|---|---|---|
| DexYCB (baseline) | H2O | 44.96 |
| ADL4D | H2O | 32.76 |

27% reduction in rr MPJPE — better cross-dataset generalisation. Significantly better mesh quality.
Downstream: Action Segmentation & Object Pose
Action Segmentation
| Features | Acc. ↑ | Edit ↑ | F1@10 | F1@25 | F1@50 |
|---|---|---|---|---|---|
| I3D | 32.77 | 41.66 | 24.59 | 18.21 | 7.12 |
| X3D | 28.99 | 34.15 | 28.50 | 19.27 | 6.85 |
| SlowFast | 45.02 | 40.78 | 36.73 | 28.86 | 16.94 |
| Pose (ADL4D) | 57.15 | 53.19 | 56.77 | 50.89 | 35.81 |
Zero-Shot Object Pose Tracking
| Model | ADD ↑ | ADD-S ↑ |
|---|---|---|
| FoundationPose | 0.47 | 0.64 |
| ICG+ | 0.53 | 0.74 |
Pose features remain camera-motion invariant; ADL4D validates as a challenging multi-subject benchmark for both action understanding and object pose methods.
Demo: ADL4D Sequences
Demo: DexYCB Sequence 4
Demo: DexYCB Sequence 6
Demo: H2O Sequences
Impact & Future Directions
Current Impact
- Deployed at TUM — Project Lab Human Activity Understanding (HAU)
- Multiple MSc and PhD projects built with markerless data from the system
- Grounds a core research topic in long-horizon context analysis with 6D human poses
- Comparable scale to frontier AI lab datasets (Meta HOT3D, CMU Panoptic) at a fraction of the cost
- Published on arXiv: 2402.17758
Future Directions
- Egocentric cameras — include already integrated ego feed into dataset
- Dense landmark models — finer granularity beyond sparse keypoints
- Beyond kitchen — expand to diverse daily-living environments